* Before you start, it is recommended that you read Python Basic Grammar and do Python Basics – Webcrawling news articles and save Excel files.https://blog.naver.com/srang_/222113557604
Python Basics – Web crawl news articles and save Excel files* Before we get started, I suggest you look at Python Basics – Image Crawling '…blog.naver.com
* The IDE of the affected project was progressed in Symmetriccharm.* If the library installation method is different from IDE, notify you that you can install the following installation method, you can install the following install package name in the terminal window.1. Analysis Talk conversation content and analyze the contents of the word cloud creation of the word cloud creation of the word cloud creation of the word and the frequency of the word usage frequency.Using WordCloud Library
인기글



Wordcloud A little wordcloud generatorpypi.org
2. Reading and Writing Text Files (1) Text File Writing Code Save the data you created through the f.write() function in the hello.txt file.* If the hello.txt file already exists, it will be overwritten.
f = open(hello.txt”, “w”, encoding=”utf-8″)f.write(“Hello, World”)f.close()
(1)Using a few lines of text file for statement, hello, world! You can store a total of 10 lines of data, from 0 to 9.

f = open(hello.txt”, “w”, encoding=”utf-8″) for in range(10): f.write(‘Hello, World! {}\n’.format(i)f.close()
(1)-2 Text File Output Hello.txt file with f.You can see the data created in write() saved.
(2) A text file reading code hello.txt file is read and outputted line by line through a print() function.* The withopen syntax is code that automatically closes a file after it is opened.
open(“hello.txt”, “r”, encoding=”utf-8″) where f: lines = f.readlines Used as: print(line)
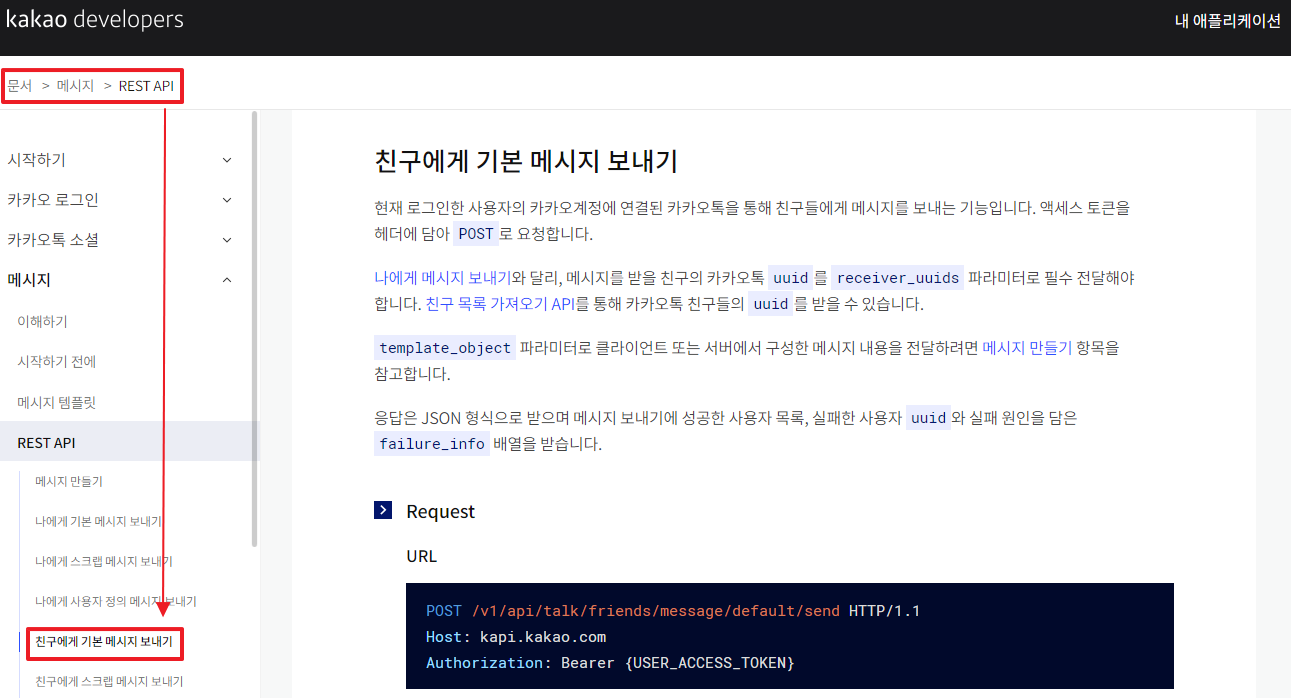
3. Create WordCloud(1) Enter the Kakao Talk chat room you want to create a word cloud for KakaoTalk content file. [Menu] → [Content of conversation] → Export Conversations → [Save] to save the file.* If you press Save, it is recommended that you change the file name to your liking when saving because the file name is too long.
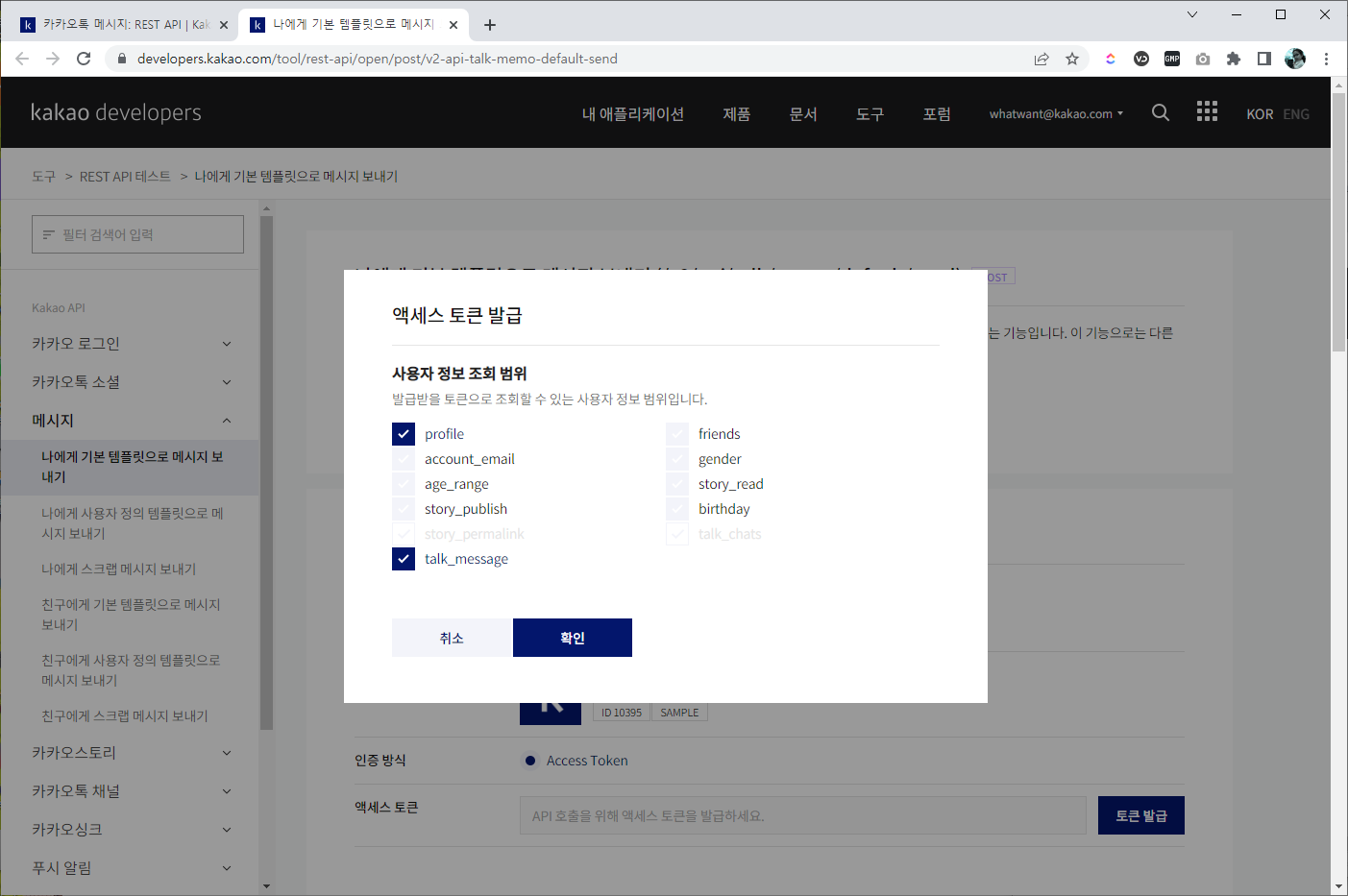
file_name = ‘File name.file_name 수에t in line txt’ # For lines, use open(file_name, “r”, encoding=”utf-8″) as f:lines = f.readlines():print(line)(2) Font search word Search the font location to change the font of a word that enters the cloud to the font you want.Import the natlistb.If you use the context_manager.tspfm# command to use the font_manager.thicを .thicf(2)(1) When the applicable code is executed.Copy the position of the desired font.* Copy content>C:\Windows\NanumBarunGothicBarunGot feature is made to be made. * If you have a Windows operating system, you must change the\ part.# # フォント ★★★★★★★★★★★★★★★★★★★C:/Windows/Fonts/Nanum Barun Gothic Bold.ttf(3) The file of the Wordcloud library is larger, so it may take a little time.* If you use the password IDE, you can use the library to create a library name of the library to create a library name of the library.Downloader→Phone IDE.wordcloud import WordCloud wc = = WordCloud (font_path=background_color=”white”, width=600, height=400)wc.generate(text)wc から取得します.to_file(result.png”)(5) You can use the WordCloud library to create a word cloud image file.You can have previously created KakaT file and save data to the text variable and save data to the text variable.wordcloudimport WordCloudtext = “with open(“KakaoTalk.txt”, “r”, encoding=”utf-8″) から、行の f: lines = f.readlines(linefont= ‘C:/Windows/Fonts/NanumBarunGothicBold.tf’wc= WordCloud(font_path=witch, background_color”, background_color”ホワイト), whit=600, white.to_file(result.png”)4. The data cleaning(1) will be created by creating accurate word cloud that you need to import data that you need to import data on the data cleaning (1).(1)A first copy of the Cao Talk System Message removalferrors.* * カカオトーク対話データを分析してみると、ユーザーが入力したチャットは「[ ]」のデータが含まれている.Therefore, if the applicable character is included in the text variable.In-Line Online: if ‘] US>’ Inline: text+= line(1)Removing user names from KakaoTalk data * Analyzing KakaoTalk chat data creates a chat as shown in the table below. Therefore, using the Spilt() method, a list is created by cutting the ” character based on it, and a string is added to the text variable only after the ” character appears twice.* * split(‘]’) The string should be separated by the method, and only the string with index number 2, which is the actual conversation content, should be obtained.[Username] [9:38 PM] Hi everyone[Username] [9:38 PM] Hi everyone[Username] [9:38 PM] Hello, 012[Username] [9:38 PM] Hello, 012Lines in line: if ‘] ‘ inline: text The < = line.Split [2](1)-3 Removing photos from KakaoTalk data * If you send a photo through KakaoTalk, the data will be transmitted as the string “photograph”.* Therefore, since you don’t want your picture to be in WordCloud, use the replace() method to change the string of your picture\nto blank.Lines in line: if ‘] ‘ inline: text The < = line.Split [2].Alternate (‘+n’)(1)-4 Remove other unnecessary words and characters* Similarly, you can use the replace() method to remove a variety of meaningless words.For line:if you are:if ‘行’]内 [line: text += line.(‘진])[2].replace(\n’ anjor).replace(\n’ anjor).replace(\n’ anjor).replace(\n’ anjor).replace(\n’ anjorz).replace(\n’ anjorz).ransplease({{}を置き換えてください)(2) WordCloud.png file creation completed5. You can copy the word cloud in the code that you want to create a word cloud under the code that you want to create a word cloud to create a word cloud.(1)If you download and enter another form of files in the Image.op(s” (‘s”) can be created and create a word cloud.* The import code on the top of the pieson file.Image Image Image Image Import npmask = = np.array(Image.open(‘cloud.png’)wc = WordCloud(font_path=”, bkg route =”, mask (textk=” and mask).to_file(result_result.png”)(2) WordCloud.png file creation completed6. Kakao Talk Conversation Word Cloud File Creation Project Final Source Code A project to create a word cloud by opening Kakao Talk conversation data with friends in Pythonfrom wordcloud import WordCloud from PIL import numpy を nptext = “with open(“KakaoTalk.txt”, “r”, encoding=”utf-8″)If you, replace the line:ext += line.spl.split-line.split-line.\n'()。 ‘replace ‘replace ‘replace ‘print’)’ (window’\n’)を置き換えますs/Fonts/NanumBarunGothicBold.ttf’wc = WordCloud(font_path=white, background_color=”white”, width=600, height=400)wc.generate(text)wc.to_file(result.png”)mask = = np.array(Image.open(‘cloud.png’))wc = = WordCloud(font_path=null, background_color=”white”, mask=generate(text)wc.to_file(result_result.png”)from wordcloud import WordCloud from PIL import numpy を nptext = “with open(“KakaoTalk.txt”, “r”, encoding=”utf-8″) For line ‘line: text += line.(‘ (line: text += line.split”)’, replace [2].\n'()。 ‘replace ‘replace ‘replace ‘print’)’ (window’\n’)を置き換えますs/Fonts/NanumBarunGothicBold.ttf’wc = WordCloud(font_path=white, background_color=”white”, width=600, height=400)wc.generate(text)wc.to_file(result.png”)mask = = np.array(Image.open(‘cloud.png’))wc = = WordCloud(font_path=null, background_color=”white”, mask=generate(text)wc.to_file(result_result.png”)from wordcloud import WordCloud from PIL import numpy を nptext = “with open(“KakaoTalk.txt”, “r”, encoding=”utf-8″) For line ‘line: text += line.(‘ (line: text += line.split”)’, replace [2].\n'()。 ‘replace ‘replace ‘replace ‘print’)’ (window’\n’)を置き換えますs/Fonts/NanumBarunGothicBold.ttf’wc = WordCloud(font_path=white, background_color=”white”, width=600, height=400)wc.generate(text)wc.to_file(result.png”)mask = = np.array(Image.open(‘cloud.png’))wc = = WordCloud(font_path=null, background_color=”white”, mask=generate(text)wc.to_file(result_result.png”)